想自己做 AI Agent?收好这份大语言模型模型指南
作者:superoo7
编译:深潮TechFlow
几乎每天我都会收到类似的问题。经过帮助构建超过 20 个 AI 智能体并在测试模型上投入了大量成本后,我总结出了一些真正有效的经验。
以下是关于如何选择合适 LLM 的完整指南。

目前的大语言模型 (LLM) 领域变化迅速。几乎每周都有新模型发布,每个模型都声称自己是“最好的”。
但现实是:没有一种模型能够满足所有需求。
每种模型都有其特定的适用场景。
我已经测试了数十种模型,希望通过我的经验,能让你避免不必要的时间和金钱浪费。
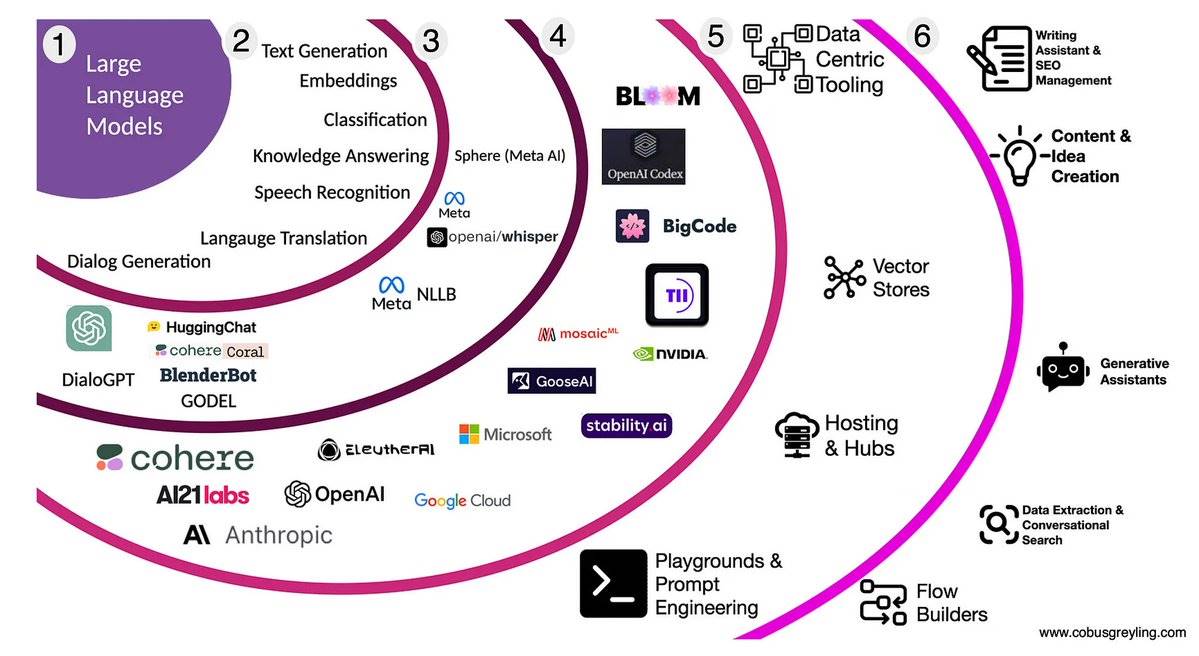
需要说明的是:这篇文章并非基于实验室的基准测试或营销宣传。
我将分享的是基于过去两年中,亲手构建 AI 智能体和生成式 AI (GenAI) 产品的实际经验。
首先,我们需要了解什么是 LLM:
大语言模型 (LLM) 就像是教会计算机“说人话”。它根据你输入的内容,预测接下来最可能出现的单词。
这一技术的起点是这篇经典论文:Attention Is All You Need
基础知识——封闭源代码与开放源代码的 LLM:
-
封闭源代码:例如 GPT-4 和 Claude,通常按使用量付费,由提供商托管运行。
-
开放源代码:例如 Meta 的 Llama 和 Mixtral,需要用户自行部署和运行。
刚接触时,可能会对这些术语感到困惑,但理解两者的区别非常重要。
模型规模并不等于性能更好:
比如 7B 表示模型有 70 亿个参数。
但更大的模型并不总是表现更优。关键在于选择适合你具体需求的模型。
如果你需要构建 X/Twitter 机器人或社交 AI:
@xai 的 Grok 是一个非常不错的选择:
-
提供慷慨的免费额度
-
对社交语境的理解能力出色
-
虽然是封闭源代码,但非常值得尝试
强烈推荐刚入门的开发者使用这个模型!(小道消息:
@ai16zdao 的 Eliza 默认模型正在使用 XAI Grok)
如果你需要处理多语言内容:
@Alibaba_Qwen 的 QwQ 模型在我们的测试中表现非常出色,尤其是在亚洲语言处理方面。
需要注意的是,该模型的训练数据主要来自中国大陆,因此某些内容可能会有信息缺失的情况。

本文地址: - 蜂鸟财经
免责声明:本文仅代表作者本人观点,与蜂鸟财经立场无关。本站所有内容不构成投资建议,币市有风险、投资请慎重。